[모두를 위한 딥러닝 시즌1] Lec06. Softmax Regression의 개념과 Cost
선형회귀의 cost function까지 살펴보고 우리는
변수가 여러개인 선형회귀 모델을 알아보았다.
바로 이전 시간에 배운 Logistic Classification 모델은 이진분류에 사용되는 모델이다.
그렇다면 우리가 분류하는 범주가 2개가 아니라 여러개라면 어떨까?

구분해야하는 범주(class)가 3개라고 가정해보자.
우리가 배운 범위 내에서 간단하게 떠올릴 수 있는 방법은 3개의 개별 classifier를 생성하는 것이다.

결국 하나의 input이 주어지면 3개의 classifier를 통과시켜서 결과를 얻게 될 것이다.
하지만 분류 해야하는 범주가 늘어난다면 너무 복잡해지지는 않을까?
따로따로 되는 계산을 줄이기 위해 Matrix Multiplication이 다시 등장한다.


이후 이 결과를 각각 시그모이드에 통과시켜서 결과를 얻을 수도 있을 것이다.
즉 여러개의 classifier를 하나로 합쳐서 더욱 간단하게 만들었다는 장점이 생겼다.
하지만 아직도 이 각각의 예측값을 한번씩 시그모이드에 넣어주어야하고, 그 결과는 0 or 1로 나오게 된다.
분류 class가 늘어나게 되면 단순한 0 아니면 1로 미리 판단해버리는 것이 아니라,
결괏값이 나왔을 때 이것을 확률을 기반으로 0과 1사이의 값으로 치환해주고 그 합이 1이되는 형태가 되면 더 좋을 것이다.
판단은 그 후에 진행하면 되기 때문이다.
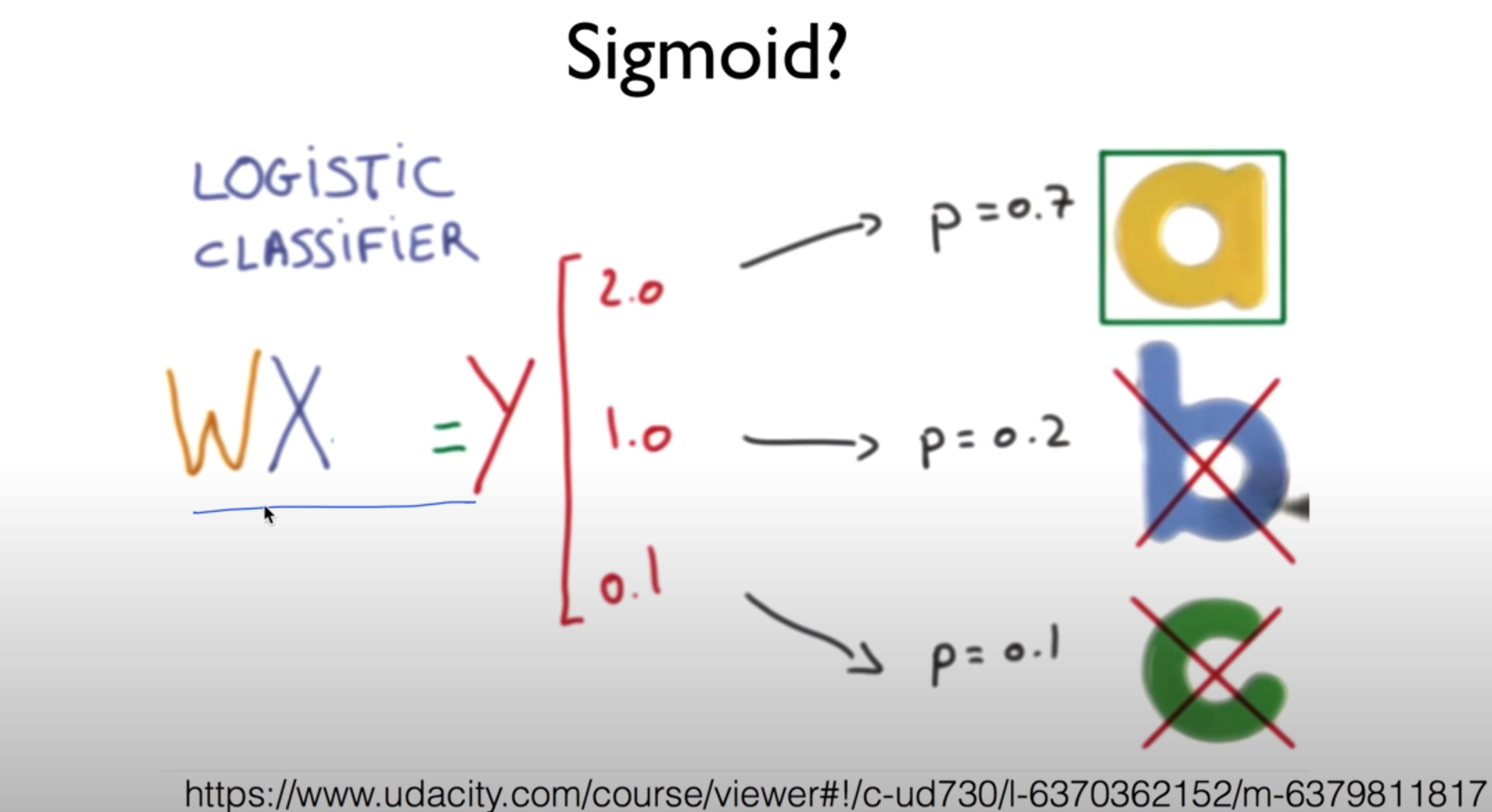
말이 복잡해지니 그림으로 살펴보자면 위와 같다.
이런 결과를 위한 것이 바로 Softmax classifier이다.

이제 확률적인 값까지 우리는 좀 더 구체적인 정보를 얻었고,
만약 그 결과 모델이 예측한 최종 값을 알고 싶다면, one-hot encoding을 통해서 그 결과를 알 수 있을 것이다.
pytorch에서는 최댓값의 인덱스를 반환하는 argmax를 이용할 수 있다.
기본적인 개념과 필요한 함수를 알아보았으니 이제는 Softmax Regression을 이용했을 때 cost function에 대해서 알아보자.
먼저 말하자면 Cross Entropy라는 cost function을 이용한다.

저번 시간에 잠깐 언급했지만, 이것을 이진분류를 위한 모델로 만들면 Binary Cross Entropy가 된다.
( i = 2, S = H(X), L1 = Y, L2 = 1-Y 로 치환하면 이해가 될 것이다)
또한 그 원리도 log함수를 그리고 몇 가지 분류를 직접 해보면 금방 이해할 수 있다.
(
영상을 참고하는 것도 도움이 될 것 같다.
https://www.youtube.com/watch?v=jMU9G5WEtBc&list=PLlMkM4tgfjnLSOjrEJN31gZATbcj_MpUm&index=15

위에서 구한 것은 한 case에 대한 cost 값이기 때문에 만약 여러 training set이 존재한다면 case마다 구한 cost를 평균낸 것이 전체 cost(loss)가 될 것이다.
여기까지가 deep learning으로 들어가기 전 regression과 classification의 기초에 대해서 배우는 수업이었다.
김성훈 교수님 덕분에 복잡한 개념도 간단하게 배우기도 했고
시즌2를 수강하며 pytorch로 직접 이용을 해봤지만 아직도
softmax, sigmoid, cost function 등 직접 이용할 때 헷갈리는 부분들이 있다.
이러한 부분은 개념을 확실히 잡은 뒤 여러 실습을 통해 해결하려고 노력해야겠다.