이 논문은 2021 CVPR에서 발표된 논문으로 기존에 연구되던 Contrastive Learning을 Dense prediction에 더욱 잘 맞도록 연구한 DenseCL의 내용을 담고있다. 사실 이 논문에 앞서서 Self-Supervised Learning을 연구하는 논문인 BYOL, SimCLR, MoCo 등을 아직 읽지 않아서 배경 지식이 많이 부족했기 때문에, 나중에 해당 논문들을 읽고 다시 읽어봐야 할 것 같다.
먼저 이번에 처음 알게 된 self-supervised learning의 개념을 정리하였다.
기존에 사용하던 supervised learning은 학습을 위한 데이터와 그에 대한 정답을 사전에 알려주고 학습을 진행하였다. 하지만 self-supervised learning의 경우는 정답 label이 존재하지 않는 데이터에서 학습을 진행하게 된다. 주로 downstream task를 위해 pre-trained network를 학습시키는 용도로 연구되어왔다.
Self-Supervised Learning
1. Pretext Task: 원본 데이터를 변형 후 원래 feature를 복원하도록 학습
- Autoencoding: 이미지를 저차원으로 변형 후 원본 복원
- Colorization: 흑백에서 원본 색상으로 복원
- Jigsaw puzzle: 이미지를 조각으로 나누고 원래 위치로 복원
2. Contrastive Learning: 서로 다른 버전의 변형된 이미지 혹은 다른 이미지와 대조하는 방법으로 학습을 진행 (유사성, 차이점 학습, positive pair, negative pair 사용 )
- SimCLR: 같은 원본의 변형된 버전을 가깝게, 원본이 다른 이미지를 멀게 학습
- MoCo: 메모리 큐를 이용한 대조 학습
3. Masked Modelin: 데이터를 가리고, 가려진 부분을 예측
- BERT: 텍스트에서 가려진 부분을 학습
- MAE(Masked Autoencoder): 일부 패치를 가리고 복원
장점: 라벨링 cost가 들지 않는다, Pre-training에 유용하다, 더 많은 데이터를 활용할 수 있다
단점: Pretext task와 downstream task가 일치하지 않을 수 있다, 대규모 계산 자원의 필요
문제 정의
이렇게 간단하게 self-supervised learning에 대해서 알아보았다. 여기서 알 수 있듯이 pre-training을 위해 사용될 수 있지만 downstream task와 일치하지 않는 경우 효율이 떨어질 수 있다는 단점이 존재한다. 즉 pre-train에서는 image level prediction(분류 문제)로 학습하였지만 실제 downstream에서는 pixel level prediction(detection, segmentation)을 수행하는 경우가 있다. 이 경우 두 task 사이에 존재하는 discrepancy로 인해서 optimal한 transfer learning이 가능하지 않을 가능성이 존재한다. 심지어 더 큰 데이터를 사용하여 분류 문제를 학습한 뒤 dense prediction task로 전이학습을 시키더라도 성능이 향상되지 않기도 한다. 따라서 dense prediction task의 pre-training과 관련된 다양한 연구가 진행되었다고 한다.
이 문제를 해결하기 위한 방법은 다양할 것이다. 먼저 pre-train 모델을 direct하게 dense(pixel) prediction으로 학습하는 것이다. 하지만 이 방법은 분류 data보다 data를 준비함에 있어서 너무 많은 시간이 소요된다는 것을 쉽게 예상할 수 있다.
다음으로 unsupervised visual pre-training으로 문제를 해결하려는 시도도 많이 존재했다. 성능이 향상되는 것이 보였지만, 여전히 앞서 언급한 gap이 사라지지 않았다. 왜나하면 대부분의 방법이 image level prediction으로 학습되었고 이것은 global feature만을 사용하였기 때문이다. 따라서 논문의 저자들은 dense prediction task를 위한 self-supervised learning의 필요성을 주장한다. 따라서 이 논문에서는 이 gap을 해결하기 위한 DenseCL 방법을 제시한다.
해결 방법 및 원리

논문의 저자가 고안한 아이디어는 먼저 dense projection head를 사용하는 것이다. 이로써 backbone network로부터 dense feature vectors를 가져오는 것이다. 이 방법으로 spatial information을 보존할 수 있고 dense output format을 만들 수 있다고 주장한다. 기존에 존재하는 global projection의 경우 single feature vector를 구하기 때문에 이미지 전반의 정보만 얻을 뿐 local feature에 대한 학습이 이루어지지 않았다는 점을 보완한 것이다. 최종적으로 DenseCL은 dense feature vector를 input으로 받아서 single global feature vector를 생성하는 global projection head와 dense feature vectors를 생성하는 dense proejction head를 병렬로 사용하여 DenseCL을 구현하였다.
다음으로 각 view에 대한 correspondence를 사용하여 각각의 local feature에 대한 positive sample을 만들어서 constrative learning을 수행한다. Local feature를 고려하기 때문에 기존에 존재하는 constrastive learning 손실함수인 InfoNCE를 dense paradigm에 맞게 수정한 손실함수를 적용한다. 이 부분은 아래에 추가로 설명한다.
마지막으로 dense prediction을 위한 self-supervised learning이므로 global projection head에 FCN을 (global average pooling은 제거, FC MLP는 1x1 conv layers로 교체) 적용한다.
이렇게 얻어진 local feature vectors를 통해 visual correspondence를 학습한다. 즉 같은 장면을 나타내는 다른 이미지에서 서로 같은 부분을 나타내는 patch를 학습하는 것이다. 이 방법으로 DenseCL은 다양한 dense prediction task에서 활용 가능한 general representation을 학습하는 것이 가능해졌다. 이 논문에서는 단순한 visual correspondence보다 dense correspondence across views를 설명한다.
Dense correspondence across Views
먼저 backgone network에서 추출한 feature map을 F라고 한다.

다음으로 dense projection head에서 추출한 dense feature vectors를 Θ라고 한다.
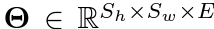
이제 dense feature vectors를 나타내는 Θ1, Θ2가 있고, 각각은 backbone feature map F1, F2를 사용했다고 가정하자. 우리가 해야하는 것은 이 둘의 유사성을 알아내는 것이다. 먼저 F1, F2가 각각 SxS의 크기를(편의를 위해 Sh=Sw=S로 가정) 가지도록 downsample한다. 이제 cosine similarity를 사용하여 Θ1의 i th vector가 Θ2 어떤 vector와 match 되는지를 계산한다.

이 식이 나타내는 의미는 F1의 feature vector인 Θ1의 i th vector가 Θ2의 ci th vector와 유사하다는 의미이다. sim() 함수는 cosine similarity를 의미하며 L2 normalized 된 두 벡터의 dot product를 계산한다.

Loss Function
먼저 쿼리 q에 대한 loss function이다. Contrastive Learning을 언급하는 SimCLR, MoCo 혹은 CLIP등에서 사용된 InfoNCE를 사용한다. 여기서 k들은 encoded key set을 나타내고, k+는 q가 해당되는 positive key를 k-는 q와 맞지 않는 negative key를 의미한다. 즉 이 손실함수를 이용하면 positive pair는 가깝게, negative pair는 멀도록 최적화가 진행된다.

InfoNCE: Mutual information (상호 정보량)을 최대화 하는 것을 목표
- 양의 샘플과의 유사도 강화, 음의 샘플과는 구분 강화
- q와 k의 상호정보량을 직접 계산하지 않고, 대조학습으로 간접적으로 MI를 최대화
다음으로 dense paradigm에 맞게 추가한 loss function이다.

앞선 loss function과 유사하지만 t는 각각의 local feature들에 대해서 encoded key set을 의미하고, r이 encoded query를 의미한다. 즉 이제는 local feature에 대한 loss를 구하는 것이다. Local feature vectors의 크기는 Sh x Sw로 구할 수 있지만 표현을 쉽게 하기 위해 Sh=Sw=S로 논문에서는 가정한다. 이외에는 앞선 InfoNCE와 동일하게 구성되어 있다. 최종 loss function은 따라서 아래와 같다.

람다는 각 loss를 balancing하는 파라미터이고 논문에서는 0.5로 설정했다. 주의해야 하는 점은 람다가 1이 되면, chicken-and-egg issue가 발생한다고 한다. 구체적으로
1. 옳지 않은 correspondence가 추출된다면 좋은 feature가 배워지지 않는 문제와
2. feature가 좋지 않은 경우 올바른 correspondence가 추출되지 않는
두 문제 모두 발생하는 것이다. 따라서 람다를 적절하게 두어 기존 single feature vector의 loss를 반영하는 것도 중요하다는 것을 알 수 있다.
유사한 논문과의 차이
논문을 쓸 당시에도 "Contrastive learning of global and local features for medical image segmentation with lomited annotations", "Unsupervised learning of dense visual representations"와 같이 비슷한 연구들이 진행되었다고 한다. 해당 논문들은 geometric transformation에 의해서 positive pair를 만들어낸다. 따라서 이 논문과는 아래와 같은 차이가 생긴다.
1. Inflexible data augmentation: 데이터 증강 방법이 positive pair에 영향을 미칠 수 있기 때문에 제약이 존재한다.
2. Limited application scenarios: 사용된 geometric transformation이 존재하지 않는다면 사용될 수 없다.
하지만 해당 논문은 data pre-processing과는 관련이 없다. 따라서 데이터 증강과 관련하여 더욱 빠르고 융통성 있는 학습이 가능해진다.
결과
- Dataset
Pre-training: MS COCO, ImageNet
Fine-tuning: VOC, COCO, Cityscapes
- Training Details
Backgone: ResNet
Projection Head: Global (128-D), Dense (128-D)
Dictionary size: 65, 536

먼저 VOC로 fine tuning한 네트워크의 object detection AP 값을 측정한 결과이다. CC는 COCO, IN은 ImageNet 으로 pretrain 하였다는 것을 의미한다. 두 경우 모두 DenseCL의 우수함을 보여주고 있다.

다음은 COCO dataset에서 Object detection과 instance segmentation을 측정한 결과이다. SOTA였던 MoCo v2보다 성능이 우세함을 알 수 있고, supervised 방법 보다도 우수한 성능을 보여준다.

다음으로는 같은 COCO 데이터에 대해서 10%의 데이터로만 fine tuning을 진행한 결과이다. 10프로의 데이터만 사용하였기에 전반적인 AP 값이 이전보다는 감소했지만 이러한 상황에서도 여전히 DenseCL이 우수한 성능을 보여주고 있다.

마지막으로 VOC와 Cityscape 데이터에서 semantic segmentation 결과이다. mIoU를 평가 지표로 사용하며 5번의 독립 시행을 평균하여 결과로 사용하였다. 그 결과 두 데이터셋 모두에서 DenseCL이 우수하였다.
Ablation Study
1. Loss weight λ

앞서 언급했던 것처럼 적절한 λ를 찾기 위해 시도했던 실험들을 보여주고 있다. 결과적으로 0.5의 람다에서 가장 좋은 결과를 보여주었고, λ가 1인 경우는 local feature vector의 loss만을 반영함으로 매우 안좋은 성능을 나타내는 것을 확인할 수 있었다.
2. Matching Strategy

correspondence matching 방식으로 위의 표와 같이 다양한 방법이 존재한다. 즉 dense correspondence를 어떤 값을 기준으로 비교할 것인가를 결정하는 것이다. 결과적으로 backbone feature F에 따라서 추출하는 것의 성능이 가장 좋은 것을 알 수 있다. 놀라운 점은 random하게 matching을 시도하더라도 MoCo v2에 비해 분류 성능에서 0.9%의 mAP 감소가 있었지만, detection에서는 1.3%의 AP 증가가 있었다는 점이다.
3. Grid Size
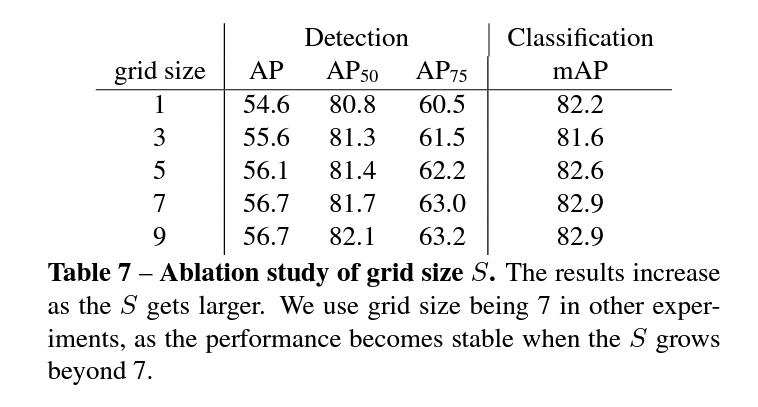
grid size, 즉 feature vector의 크기인 S에 해당하는 값을 무엇으로 설정할 것인가 또한 성능에 영향을 미치는 요소이다. S가 1인 경우는 single feature vector에 해당하므로 MoCo v2와 거의 동일했다. 하지만 새롭게 추가된 dense projection head의 parameter에서 차이가 존재했다. 또한 dense contrastive learning이 독립적인 dictionary를 유지한다는 점에서 차이가 있었다. 최종적으로 S가 9 이상에서는 성능 향상이 미비했고, 저자는 S를 7로 설정했다.
4. Training schedule

COCO 데이터로 pretrain 된 MoCo와 DenseCL의 epoch에 따른 AP 값이다. 같은 조건에서 DenseCL의 우수함을 살펴볼 수 있다.
또한 1600 epoch를 가지는 COCO로 pretrain 된 DenseCL과 200 epoch를 가지는 ImageNet으로 pretrain 된 MoCo v2를 살펴보더라도 Dense CL의 성능이 좋다는 것도 발견했다고 한다 (57.2% AP vs 57.0% AP). ImageNet의 data 수가 10배 더 많은 것을 고려하면 DenseCL의 우수함을 알 수 있다.

마지막으로 epoch의 증가에 따른 성능 향상을 DenseCL의 성능 향상을 보여주는 표이다.
결론

DenseCL은 dense prediction에 더욱 적합한 pre-trained model을 위한 contrastive learning을 고안한 논문이다. 위의 사진과 같이 contrastive learning을 적용한 다른 모델들보다 local feature를 더욱 잘 잡아내며 dense correspondence에서 눈에 띄는 향상이 있음을 알 수 있다. 이해하기 쉬운 문제점을 직관적인 방법으로 해결하려 했다는 점에서 의미있는 논문이라고 생각한다.
'딥러닝 > Paper Review' 카테고리의 다른 글
| [Paper Review] Spatial Transformer Networks (0) | 2025.01.19 |
|---|---|
| [Paper Review] Jigsaw Clustering for Unsupervised Visual Representation Learning (1) | 2025.01.18 |
| [Paper Review] Going deeper with convolutions (1) | 2025.01.07 |
| [Paper Review] Very Deep Convolutional Networks For Large-Scale Image Recognition (0) | 2025.01.06 |
| [Paper Review] Deep Residual Learning for Image Recognition (1) | 2024.11.11 |